ロボット学習に関する取り組み
ロボティクスと機械学習の融合領域は「ロボット学習(robot learning)」などと呼ばれ,近年発展の著しい分野です.ロボット学習の中心となるトピックは強化学習や模倣学習であり,これまで強化学習や模倣学習をはじめとする様々な研究テーマに取り組んできています.
深層強化学習における多様な解の発見
強化学習において,最適な行動価値関数を実現する方策は複数ある場合があることが知られています. しかし,既存の強化学習の手法のほとんどは,そのうち一つの解を確率的に発見するものです. 本研究では,深層強化学習において,多様な解を発見する手法を提案しています. 右の動画はオンライン強化学習における結果を示していますが、オフライン強化学習の問題設定に対してもアルゴリズムを提案しています。
T. Osa and T. Harada. Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning. Proceedings of the International Conference on Machine Learning (ICML), 2024.
[ arXiv][ website]
T. Osa, V. Tangkaratt and M. Sugiyama. Discovering Diverse Solutions in Deep Reinforcement Learning by Maximizing State-Action-Based Mutual Information. Neural Networks, Vol. 152, pp. 90-104.
[ arXiv][ paper] [ website ]
解の潜在空間の学習による軌道計画
ロボットの動作計画を行う手法は長年研究されてきましたが,そのほとんどは単一の解を発見するのみです. しかし, 実際にはタスクを実現するための軌道が無数に存在することも多く,そのような場合にユーザーの求める軌道が出てくるように 動作計画の手法をチューニングするには専門知識を必要とします.本研究では,解の潜在空間を学習し,無数の解をニューラルネットワークでモデル化することによって ユーザーが直感的に欲しい軌道を選択することのできる手法の構築を目指しています.
T. Osa. Motion Planning by Learning the Solution Manifold in Trajectory Optimization,
The International Journal of Robotics Research (IJRR), Vol. 41, No. 3, pp. 291-311.
[ arXiv ][ paper]
パワーショベルの自動化に向けた掘削動作計画のための深層強化学習
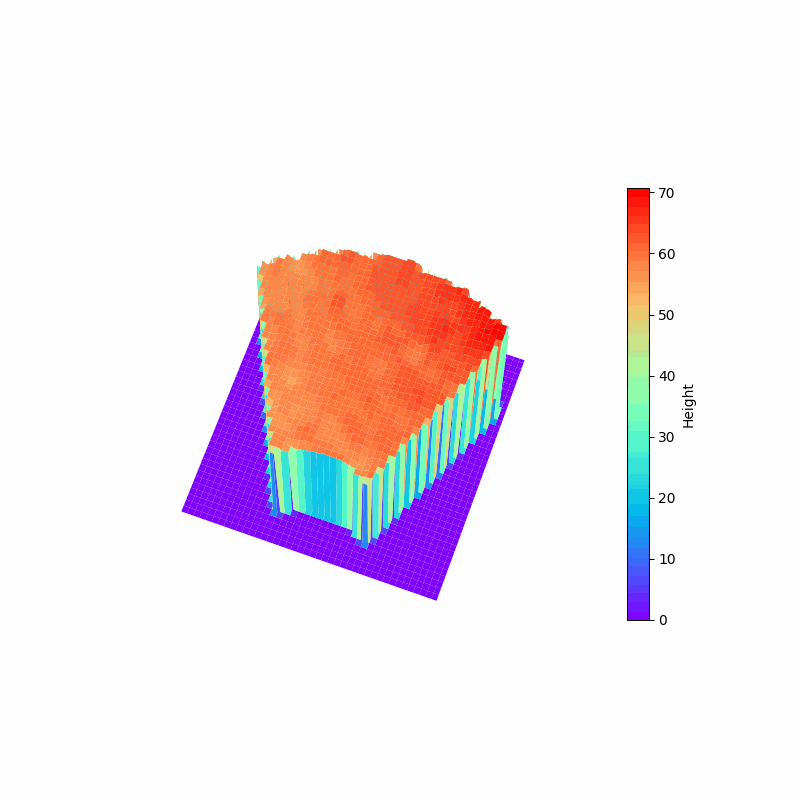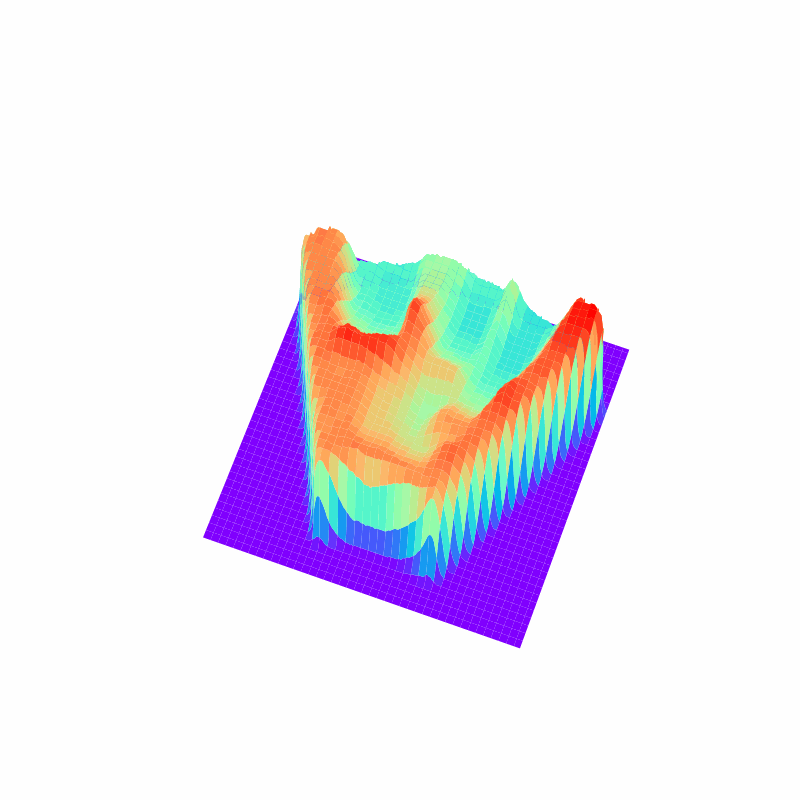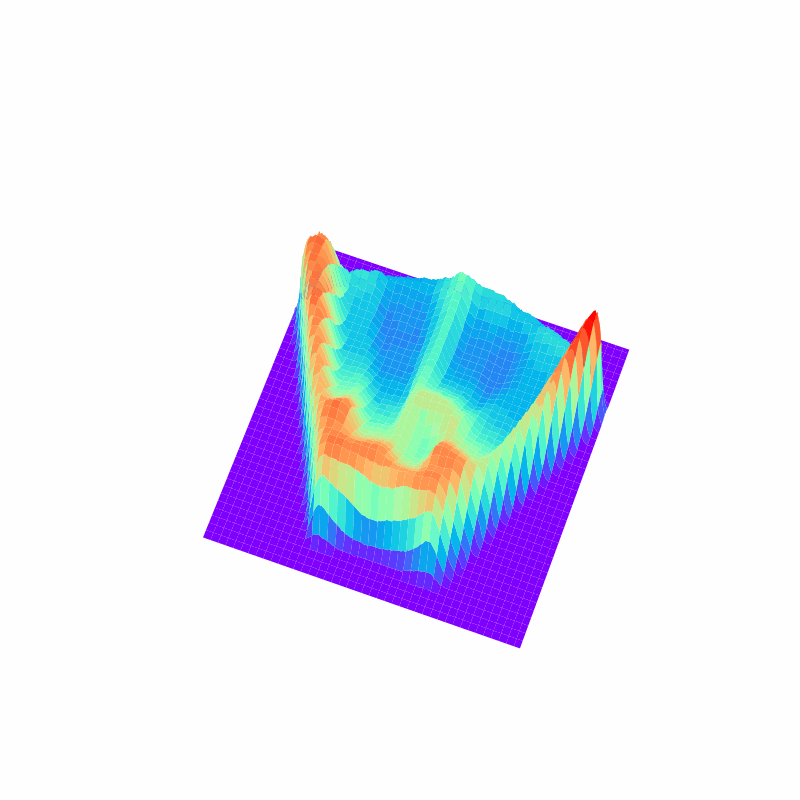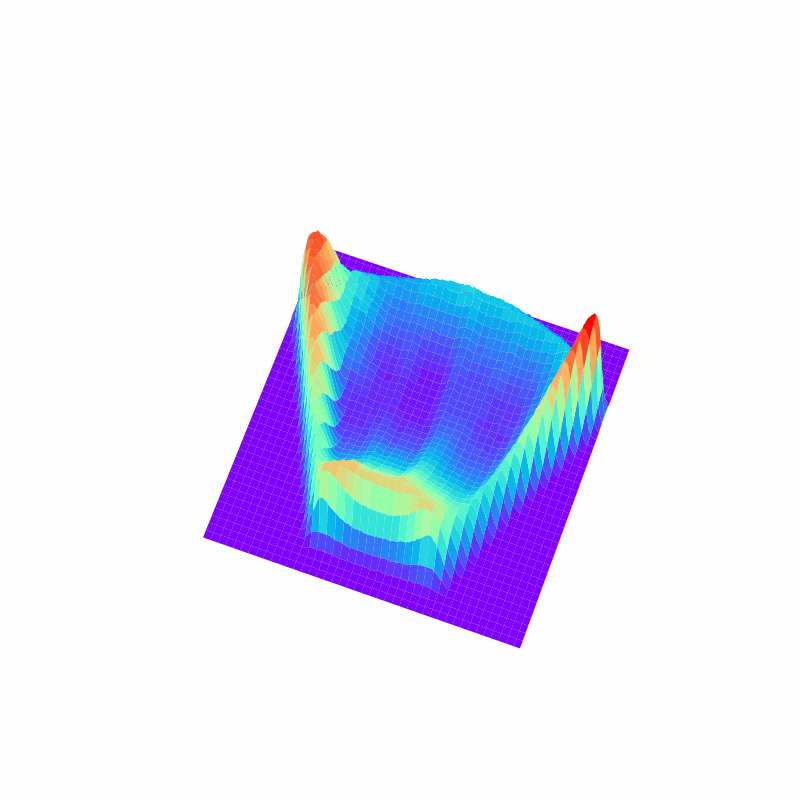
建設業においても,AIやロボットの技術の導入が近年進んでいます.本研究では,パワーショベルの自動化を目指して,地形の深度画像に基づいてバケットの軌道を計画する方策を学習する手法を開発しました. 論文では,敵対的サンプルを用いてQ関数を効率よく学習するアルゴリズムや,SACやTD3などのActor Critic法よりもQt-Optと呼ばれる手法のほうが掘削動作の学習には適していることなどを示しています.
T. Osa and M. Aizawa, Deep Reinforcement Learning with Adversarial Training for Automated Excavation using Depth Images,
IEEE Access, Vol. 10, pp. 4523-4535, 2022.
[ paper(open access)]
T. Osa, N. Osajima, M. Aizawa, T. Harada, Learning Adaptive Policies for Autonomous Excavation Under Various Soil Conditions by Adversarial Domain Sampling,
IEEE Robotics and Automation Letters, Vol. 8, No. 9, pp. 5536-5543, 2023.
[pdf][ publisher website]
多峰性最適化による軌道計画
ロボットを動かくためには,動作計画を最初に作ることが欠かせません. ロボットの動作計画を行うソフトウェアは数多く存在しますが,そのほとんどは,単一の解を提示してくれるものです. しかし, 実際にはタスクを実現するための軌道は複数存在することがあります.本研究では,コスト関数の多峰性を考慮することで 複数の解を導き出す手法を提案しています.
T. Osa. Multimodal Trajecotry Optimization,
The International Journal of Robotics Research (IJRR), Vol. 39(8) 983–1001, 2020.
[ arXiv ]
階層型深層強化学習
実世界のタスクの多くは階層的な構造をとっており,その構造を理解することが効率的なスキルの獲得へと役立ちます. 本研究では,深層強化学習において階層構造をもった方策を学習するための手法を提案しています.
T. Osa, V. Tangkaratt, and M. Sugiyama. Hierarchical Reinforcement Learning via Advantage-Weighted Information Maximization,
International Conference on Learning Representation (ICLR), 2019.
[ arXiv ]
エキスパートのデモンストレーションに基づく軌道最適化
軌道計画には様々なアプローチがありますが,本研究では,模倣学習と軌道最適化の二つのアプローチをつなげることを目的として 軌道計画法を提案しています.
T. Osa, A. M. Ghalamzan, E., R. Stolkin, R. Lioutikov, J. Peters, and G. Neumann. Guiding Trajectory Optimization by Demonstrated Distributions, IEEE Robotics and Automation Letters (RA-L), Vol.2, No.2, pages 819-826, 2017.
[ paper ]
階層強化学習による複数の把持タイプの獲得
把持には様々なタイプがあることが示唆されていますが,複数の把持タイプを同時に学習し,さらにそれらをいかに使い分けるかも学習するという階層型強化学習を 本研究では提案しています.
T. Osa, J. Peters, G. Neumann. Experiments with Hierarchical Reinforcement Learning of Multiple Grasping Policies, Proceedings of the International Symposium on Experimental Robotics (ISER), 2016.
[ paper ]
手術の自動化に向けた実時間軌道計画と力制御
ロボット手術を自動化するには,動的に変化する系において,実時間で軌道計画を行う必要があります.また,柔軟な物体を扱うために,ロバストな力制御を行うことも必要になります. 本研究では,空間的軌道および接触力のプロファイルを実時間で計画し,ロバストに追従する手法を提案しています.
T. Osa, N. Sugita, and M. Mitsuishi, Online Trajectory Planning and Force Control for Automation of Surgical Tasks, IEEE Transactions on Automation Science and Engineering, 2017
[ paper ]